0.2.7 Hashing
A hash table is a data structure used to maximize the speed with
which a stored data item can be accessed. Operations typically
defined for hash tables are item insertion, lookup, and deletion. The
complexity of an average search operation is 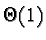 - constant
time. In many hash schemes a worst case bound for search operation
complexity is O(n). The price for such speed, as we will see, is
space.
- constant
time. In many hash schemes a worst case bound for search operation
complexity is O(n). The price for such speed, as we will see, is
space.
A hashing table data structure is usually implemented as a large
array. Whenever an item must be added to the hash table it is not simply added at the end of the structure. Instead a function
called a hash function
determines the location at which a given item is stored based,
somehow, on some attribute of the item in to be stored. This computed
location is called an item's hash value.
The value being hashed is sometimes called the pre-image.
In order to insert a new item into a hash table it is necessary to
compute the hash value of the item. Once the hash value of the item
is known, the insertion routine looks in the table at the location
specified by the hash value. If this table location is empty the new
item can be inserted outright. However if this location in the table
is already in use by some other data item an alternate strategy must
be used. This occurrence is known as a collision
and, as we will see, there are many ways of handling collisions.
Looking up an item in the hash table entails computing where the item
would be stored by finding its hash value then checking the table at
that location. Deleting an item is just as straightforward.
|